



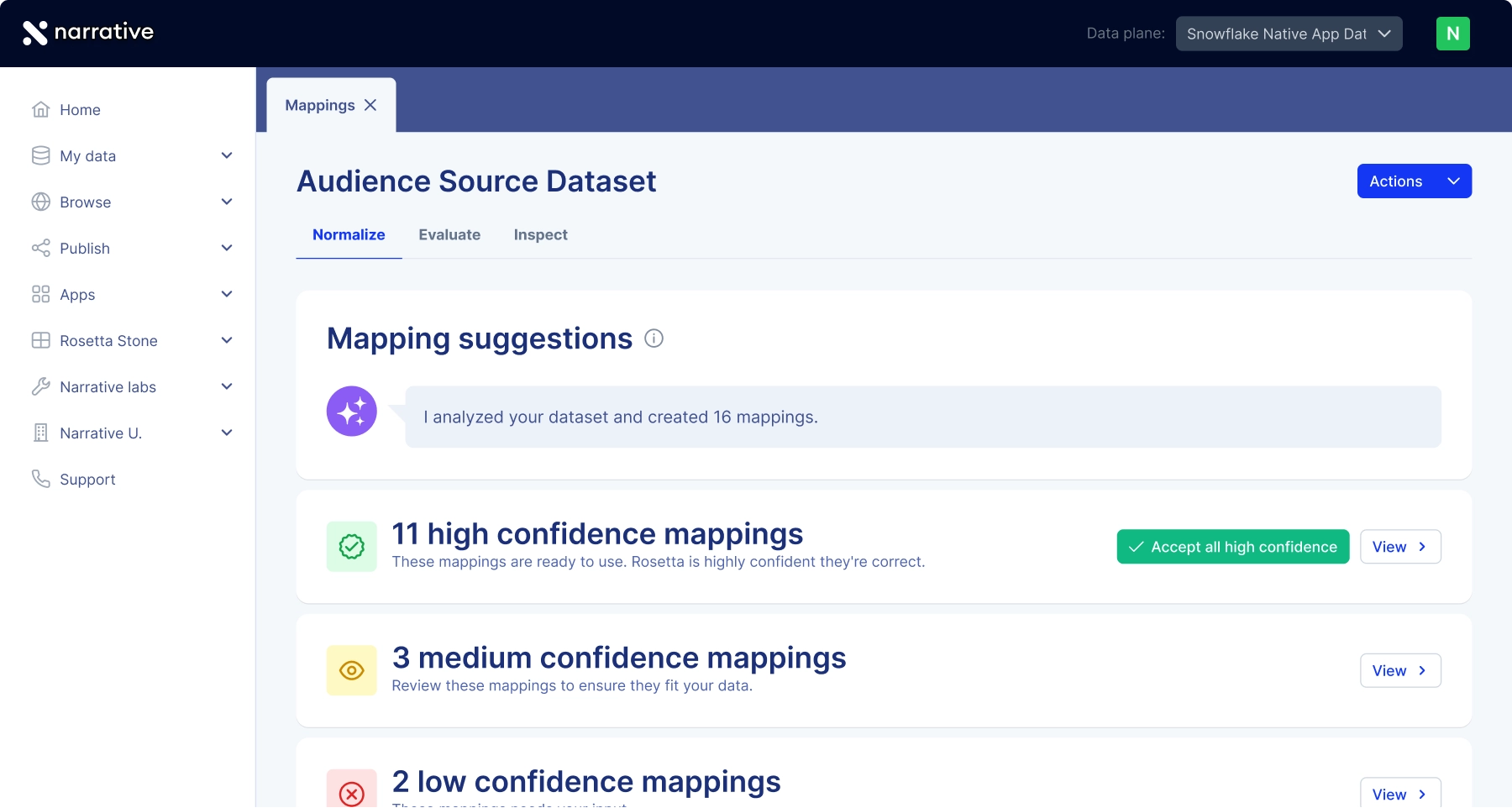
ROSETTA STONE NORMALIZATION ENGINE
Normalized data opens doors
Rosetta Stone Normalization Engine rewrites incompatible datasets in a singular, universal language. What used to take weeks of engineering, now happens automatically at query time.
Incompatible data comes at a cost
Somewhere between mapping spreadsheets and stalled partnerships, you pay the price. Every week, across every team, on every new integration.
Constant integrations
Map the fields, build the pipeline, and pray nothing breaks.
Campaign delays
Incompatible data costs you time and partnerships.
Underutilized talent
No time for strategy, or anything that drives the business forward.
What changes when your data can communicate
Here’s what your data can look like on the other side
No pipeline rebuilds
Upstream changes no longer break everything downstream
Go live fast
Measure in days instead of engineering sprints
Auto data mapping
Third-party and partner data works together automatically
More time on decisions
Redirect attention from monotonous data prep to tasks that matter
Stop productivity from getting lost in translation
Ready for deployment when you need it without custom pipelines, schemas, or interruptions
The solution
Rosetta sets the standard
Rosetta Stone reads whatever format your data arrives in and maps it to a common language automatically.
The solution
Schema changes stop being your problem
When something changes upstream, Rosetta adjusts. Your pipelines stay intact and your team stays focused.
The solution
You get back to work that matters
Automating data prep turns hours spent mapping fields and rebuilding pipelines into decisions, strategy, and partnerships.
How it works
The best tech is the kind you don’t need to think about
Rosetta Stone runs inside your existing environment, normalizing data at query time without any upfront setup or ongoing maintenance from your team for consistent, clean data when you need it.
Rosetta Stone Attributes
A universal catalog that acts as a shared language across every source, every partner, every query.
Automated mappings
AI generates field-level mappings at query time, circumventing traditional ETL bottlenecks.
Narrative Anywhere
Normalization runs inside your own cloud environment using Cortex,Bedrock, or fine-tunedmodels
Row-level classification
ML and LLM-powered classification handles the edge cases when schema logic can't.
Your team. Your data. Neither belong in silos.
Three ways to get interoperable data under the same governance layer
For marketers
Reach broader audiences without waiting on other teams.
Build segments, activate campaigns, and measure outcomes on data that's already aligned to your schema, not data that's stuck in an integration backlog.

For analysts
Join any dataset to any other, without the reconciliation.
Query across first-party, partner, and marketplace data the moment it lands with every field already mapped, and every value already aligned.

For engineers
Stop maintaining pipelines you didn't want to write in the first place.
Replace per-source mapping, per-schema reconciliation, and per-integration babysitting with a normalization layer that runs at query time. The plumbing becomes infrastructure and your team focuses on the work only your engineers can do.
Why it's different
Rosetta Stone Truths
Normalization belongs at query time.
Rigid ETL pipelines normalize data upfront. Changes upstream? Back to the drawing board. Rosetta Stone normalizes at the point of collaboration and not a minute before. Schema changes are someone else’s problem now.

Mapping is a machine’s task.
Manual schema work is slow, brittle, and doesn't scale. Rosetta's ML identifies that attributes like "gender," "is_female," and "sex_code" all mean the same thing. Even for fields it's never seen before.

In-house data processing is secure data processing.
Moving data to normalize it exposes it to risk, compliance headaches, and latency. Running normalization inside your own environment is safer and more convenient for all.
Your schema is yours.
Legacy vendors normalize your data their way, on their terms, inside their environment. When you train on your own custom attributes with Rosetta, that knowledge becomes your leverage, not theirs.
Proven results
Hours and budget back. Data working.
19%
revenue increase from existing data
99.9%
reduction in classification cardinality
64
languages normalized
Proven Results
Reach without compromise
“Partnering with Narrative.io has empowered us to seamlessly scale our offerings across diverse social platforms. Ultimately, this collaboration has been key to achieving our objective: engaging with our customers exactly where they are."
Dennis O'Donnell, Head of Ad Product
The Weather Company

“What I am looking for is a #RosettaStone. I don’t have the resources to pick through endless data sets and clean and harmonize them. I am calling it the great marketing emergency. We’ve got all this data, but we need #AI to stitch it together as a means to help our clients drive growth. We have the ability to have a fluid conversation with the consumer at the different points in their journey.”
Domenic Venuto, Chief Product & Data Officer
Horizon

“Traditional commerce media models often expose brands to unnecessary privacy risks by moving data into third-party environments. Our work with Narrative eliminates that risk while unlocking sophisticated audience-building capabilities that deliver real outcomes.”
Marni Schpario
Block

Resources
Insights, stories, & resources for the teams building modern data infrastructure.
Blog
•
4
Mins
Narrative Reimagines the Marketplace: A Composable Hub for Data and AI Work


Blog
•
4
Mins
With Publicis' Acquisition of LiveRamp, Switzerland Just Picked a Side

Blog
•
4
Mins
Clean Rooms Were Necessary. They Were Never Enough.

Blog
•
3
Mins
Activate Your Audiences Across PubMatic's Sell-Side Platform



Blog
•
4
Mins
Data Marketplaces Should Work Like Infrastructure, Not Catalogs
Ask Us Anything
Straight answers to real customer questions.
Most teams are normalizing live data within days of connecting their first sources — not months. There's no multi-quarter implementation, no professional services dependency, no bespoke build required. You connect your sources, define what coherence looks like for your use case, and Narrative does the translation work. The timeline question is usually less about setup and more about how quickly your team can act on data that's finally consistent.
Those tools move data and act on it. They don't normalize it. They're built on the assumption that the data arriving is already clean, consistent, and semantically coherent — and in most real-world data partnerships, it isn't. Narrative is the layer that makes your existing collaboration and activation infrastructure work the way it was designed to. The teams getting the most from their data stack are typically the ones who've solved normalization first.
Most teams do, at first. The problem isn't the initial build — it's everything after. Every partner schema change breaks it. Every new data source requires rebuilding it. Every team transition means relearning it. The engineering debt compounds faster than the business value accrues. Narrative replaces a perpetual maintenance burden with infrastructure that's designed to absorb that complexity so your team doesn't have to.
Data and analytics teams at companies where external data is a core business input — not a supplement. Typically organizations that are buying data at scale, monetizing their own data assets, or running structured data partnerships with other companies. If your team is spending meaningful engineering time just making external data usable, that's the problem Narrative is built to eliminate.
AI models don't tolerate inconsistency. When a "user" in one dataset isn't recognized as the same "user" in another — different schemas, different taxonomies, different identifiers — your models train on noise and your outputs reflect it. Narrative normalizes data at the source so the AI layer above it is working with signal. Garbage in, garbage out isn't an AI problem. It's a normalization problem.
Your warehouse stores data. Your CDP activates it. Narrative normalizes it — resolving the semantic inconsistencies that make data from different sources incompatible before it ever reaches those tools. We don't replace your stack. We fix the layer underneath it that your stack assumes is already solved.