



I'm trying to...
Normalize
Turn raw, messy data into labeled, structured signals without ever moving it out of your environment. Narrative classifies, normalizes, and categorizes data inside your warehouse, with the precision your use cases require.
trusted by global leaders











.png)



























.png)





























Today
Normalization is too important to be a fragmented project.
One team labels, another categorizes, a third merges results back together, pipelines break, definitions drift, and the model that worked last quarter is already stale. The work compounds, and the data you need is still waiting to be useful.
NORMALIZE FIRST
INTELLIGENT NORMALIZATION
ANYWHERE YOU ARE
REPEATABLE PROCESS
NORMALIZE FIRST
Common ground before classification.
Every classification model is only as good as the data going in. Narrative resolves schema drift, naming conflicts, and value variations on arrival, so the inputs are consistent before the work begins.

INTELLIGENT NORMALIZATION
Machine learning, LLMs, and human feedback — in one loop.
Narrative pairs continuous machine-learning models with LLM-driven extraction and a structured human-feedback loop. ML scales the routine, LLMs handle the ambiguous, and human review tunes both. The output gets sharper every cycle.

ANYWHERE YOU ARE
Models that run where your data sits.
Narrative’s registered models and functions are accessible via Snowflake SQL — runnable from any analyst’s workbench, with zero data egress. No separate data plane to stand up, no pipelines to maintain.

REPEATABLE PROCESS
Normalize, dedupe, label, categorize, rejoin.
Classification isn’t a single step — it’s a sequence. Narrative’s pipeline runs normalization, deduplication, labeling and training, categorization and extraction, and rejoin in a single flow with every stage visible, auditable, and under your control.

PRODUCTS
Turn raw data into trusted signal.

Intelligent Normalization

Humans in the Loop
Where the AI runs out of certainty, your experts pick up.
The edge cases that mappings, ML, and LLMs can't confidently resolve route to a structured human review queue. Every resolution does double duty: it classifies the record now, and it becomes training data that teaches the AI to handle the next case automatically.
Proven results
Cleaner data. Faster work. More signal.
Proven Results
Reach without compromise
“Partnering with Narrative.io has empowered us to seamlessly scale our offerings across diverse social platforms. Ultimately, this collaboration has been key to achieving our objective: engaging with our customers exactly where they are."
Dennis O'Donnell, Head of Ad Product
The Weather Company

“What I am looking for is a #RosettaStone. I don’t have the resources to pick through endless data sets and clean and harmonize them. I am calling it the great marketing emergency. We’ve got all this data, but we need #AI to stitch it together as a means to help our clients drive growth. We have the ability to have a fluid conversation with the consumer at the different points in their journey.”
Domenic Venuto, Chief Product & Data Officer
Horizon

“Traditional commerce media models often expose brands to unnecessary privacy risks by moving data into third-party environments. Our work with Narrative eliminates that risk while unlocking sophisticated audience-building capabilities that deliver real outcomes.”
Marni Schpario
Block

OTHER USE CASES
Different jobs, same foundation.

SECURELY COLLABORATE
Share data without ever shipping it.
Run collaboration in place — your data, your cloud, your governance. Make secure sharing the default, not the exception.
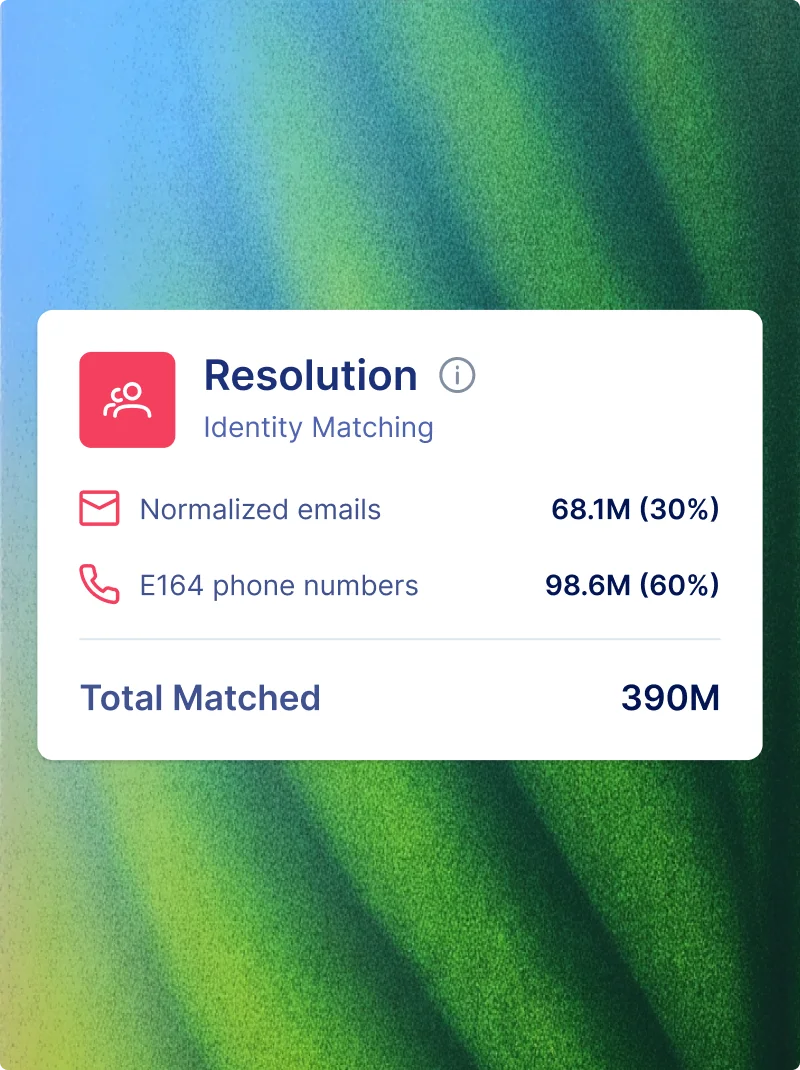
BUILD MY OWN IDENTITY GRAPH
Own the spine your business runs on.
Configure match logic, swap providers on demand, pay only for net-new identities resolved. Your graph, deployed inside your cloud, under your control.
ENRICH
Add the attributes that make targeting precise.
Augment first-party data with a marketplace of normalized providers and hundreds of mapped attributes — joined to your customer file in your cloud, ready to drive segmentation, targeting, and measurement.
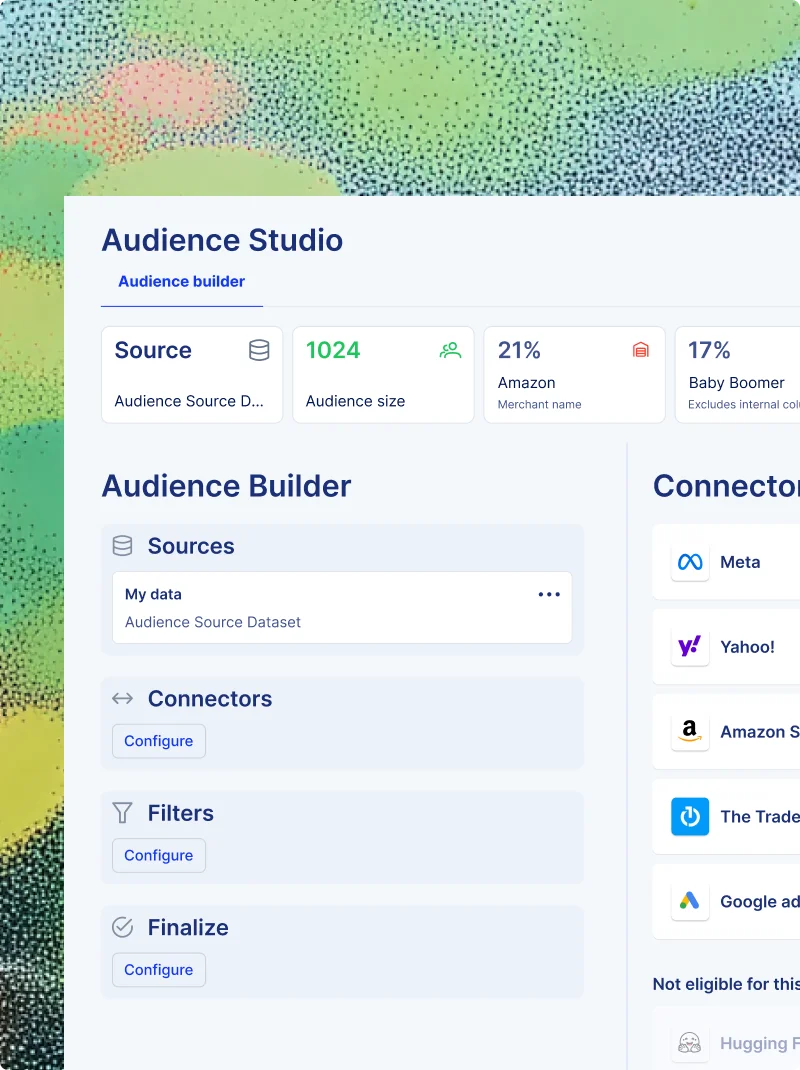
ACTIVATE AUDIENCES
Get audiences from definition to delivery in hours.
Push resolved-person audiences to every DSP, ad platform, and CRM with pre-built Connectors. Compliance rides along; activation lag goes away.

MONETIZE
Sell your data, keep your control.
Package, price, and license data on your terms. Buyers query it in place under your contracts and access rules with no bulk shipping, and no per-buyer custom prep.
Resources
Insights, stories, & resources for the teams building modern data infrastructure.
Blog
•
4
Mins
Narrative Reimagines the Marketplace: A Composable Hub for Data and AI Work


Blog
•
4
Mins
With Publicis' Acquisition of LiveRamp, Switzerland Just Picked a Side

Blog
•
4
Mins
Clean Rooms Were Necessary. They Were Never Enough.

Blog
•
3
Mins
Activate Your Audiences Across PubMatic's Sell-Side Platform



Blog
•
4
Mins
Data Marketplaces Should Work Like Infrastructure, Not Catalogs
Ask Us Anything
Straight answers to real customer questions.
Most teams are normalizing live data within days of connecting their first sources — not months. There's no multi-quarter implementation, no professional services dependency, no bespoke build required. You connect your sources, define what coherence looks like for your use case, and Narrative does the translation work. The timeline question is usually less about setup and more about how quickly your team can act on data that's finally consistent.
Those tools move data and act on it. They don't normalize it. They're built on the assumption that the data arriving is already clean, consistent, and semantically coherent — and in most real-world data partnerships, it isn't. Narrative is the layer that makes your existing collaboration and activation infrastructure work the way it was designed to. The teams getting the most from their data stack are typically the ones who've solved normalization first.
Most teams do, at first. The problem isn't the initial build — it's everything after. Every partner schema change breaks it. Every new data source requires rebuilding it. Every team transition means relearning it. The engineering debt compounds faster than the business value accrues. Narrative replaces a perpetual maintenance burden with infrastructure that's designed to absorb that complexity so your team doesn't have to.
Data and analytics teams at companies where external data is a core business input — not a supplement. Typically organizations that are buying data at scale, monetizing their own data assets, or running structured data partnerships with other companies. If your team is spending meaningful engineering time just making external data usable, that's the problem Narrative is built to eliminate.
AI models don't tolerate inconsistency. When a "user" in one dataset isn't recognized as the same "user" in another — different schemas, different taxonomies, different identifiers — your models train on noise and your outputs reflect it. Narrative normalizes data at the source so the AI layer above it is working with signal. Garbage in, garbage out isn't an AI problem. It's a normalization problem.
Your warehouse stores data. Your CDP activates it. Narrative normalizes it — resolving the semantic inconsistencies that make data from different sources incompatible before it ever reaches those tools. We don't replace your stack. We fix the layer underneath it that your stack assumes is already solved.