



I'm trying to...
Build My Own Identity Graph
Stop renting an identity spine. Build your own inside your cloud, on your rules, with the IDs you decide matter, and the providers you can swap on demand. The result: one customer, seen across every device, channel, and partner.
trusted by global leaders











.png)



























.png)





























Today
Stop renting your customer view.
Off-the-shelf graphs make you a tenant in someone else’s infrastructure: fixed match logic, foreign IDs, opaque scoring, and a bill that grows every quarter. When the business changes, the graph doesn’t.
OWN THE SPINE
CONFIGURE THE LOGIC
PLUGGABLE PROVIDERS
INCREMENTAL MATCH PRICING
OWN THE SPINE
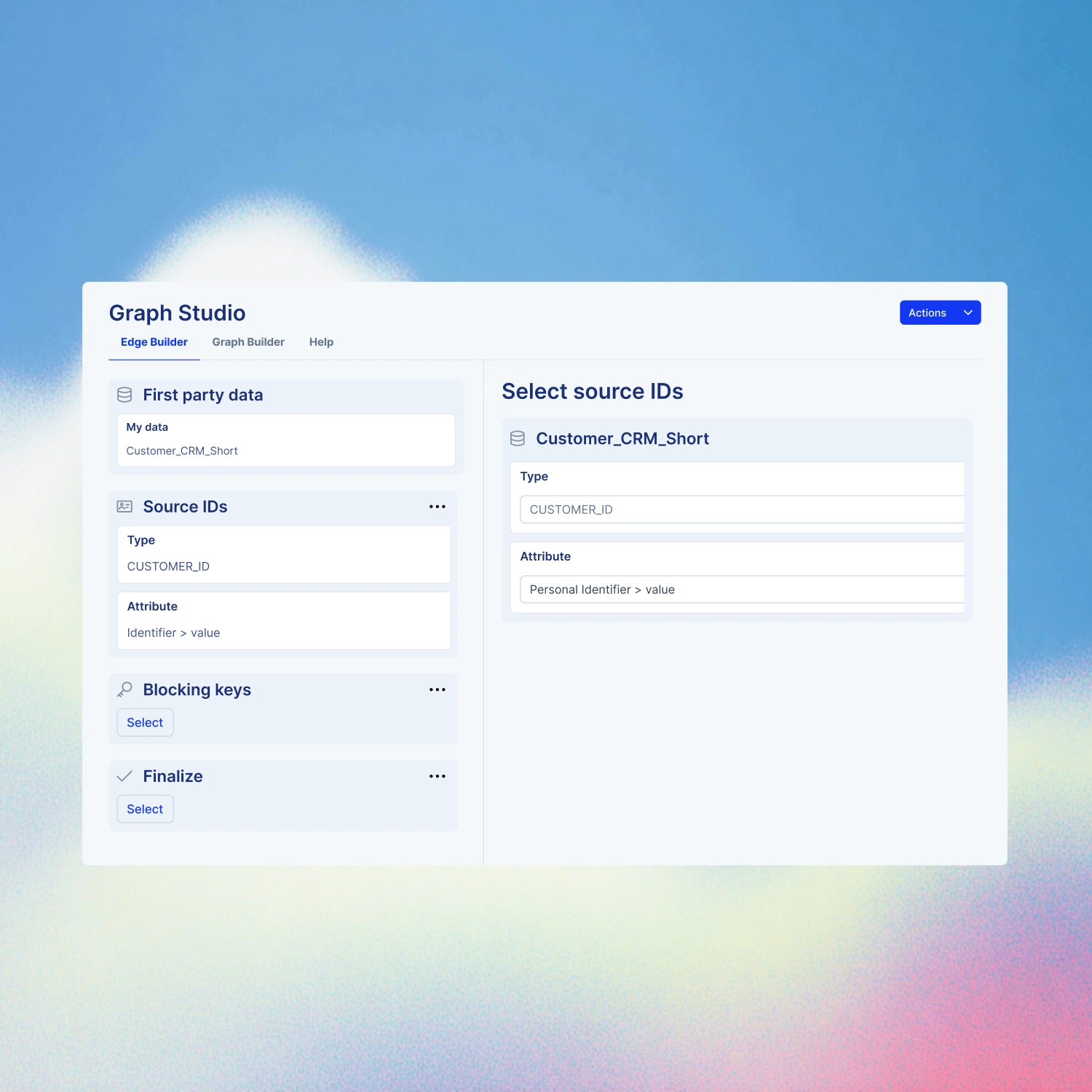
Your graph, deployed inside your cloud.
Narrative’s Identity Orchestrator runs natively where your data already lives. Your identity spine sits under your governance, your controls, your keys.
CONFIGURE THE LOGIC
Match rules tuned to your business — and visible to your team.
Configure deterministic and probabilistic matching, edge thresholds, and resolution windows per use case. Every match decision is fully inspectable: no opaque scoring, black-box thresholds, or surprises in production. The match logic for measurement doesn’t have to be the match logic for reach.
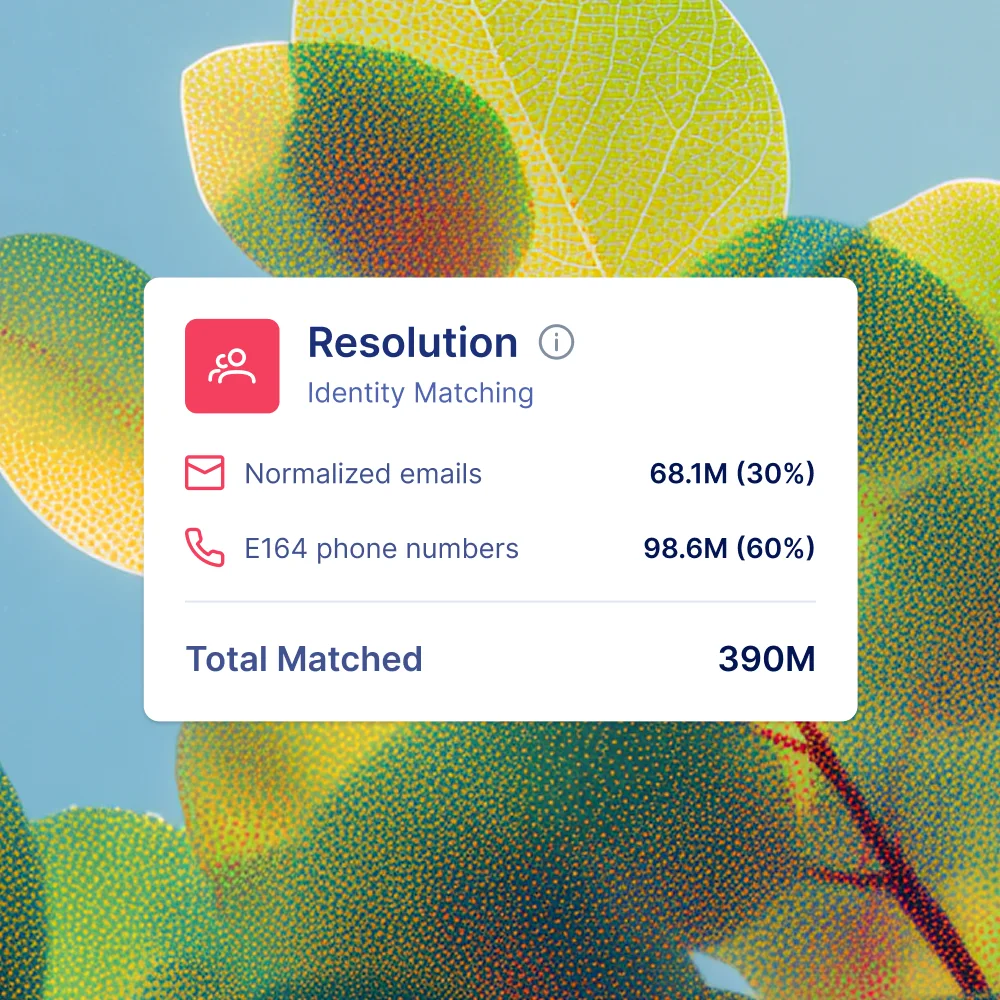
PLUGGABLE PROVIDERS
Add, swap, or test partners without rebuilding.
Treat third-party identity providers as inputs to your graph, not the graph itself. Test new edges and layer in new sources without rebuilding the spine or your strategy.
INCREMENTAL MATCH PRICING
Pay for net-new identities, not the same person twice.
Most identity graphs charge per match every time. Narrative’s incremental match pricing means you only pay for net-new identities resolved. The math finally works in your favor.

Why Narrative?
Own the graph your business runs on.

Identity Orchestrator

Rosetta Stone Normalization Engine
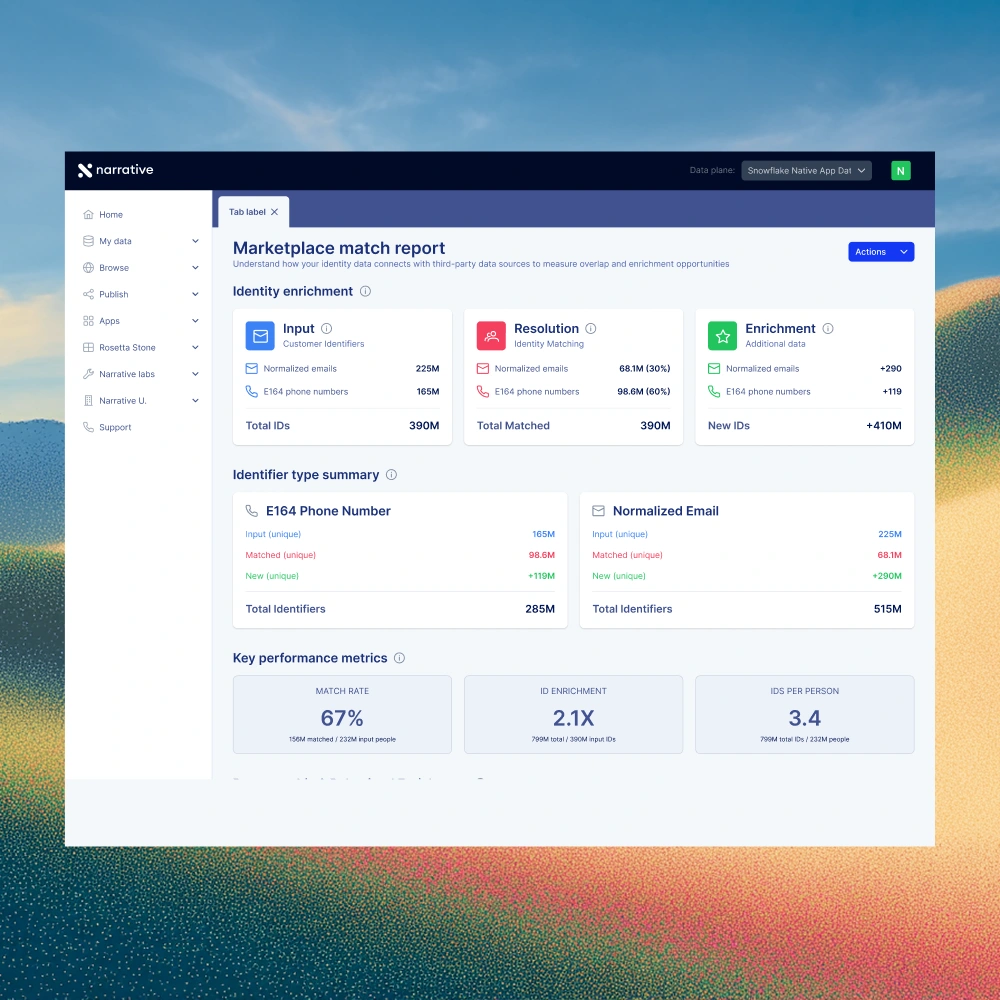
Identity resolution starts with normalized inputs.
Harmonize the schema, naming, and value conflicts across every source feeding your graph, so the matching logic operates on consistent ground instead of reconciling fifty versions of "email." Cleaner inputs mean sharper matches and a graph you can actually trust to drive decisions.
PROVEN RESULTS
Reach without compromise
“Partnering with Narrative.io has empowered us to seamlessly scale our offerings across diverse social platforms. Ultimately, this collaboration has been key to achieving our objective: engaging with our customers exactly where they are."
Dennis O'Donnell, Head of Ad Product
The Weather Company

“What I am looking for is a #RosettaStone. I don’t have the resources to pick through endless data sets and clean and harmonize them. I am calling it the great marketing emergency. We’ve got all this data, but we need #AI to stitch it together as a means to help our clients drive growth. We have the ability to have a fluid conversation with the consumer at the different points in their journey.”
Domenic Venuto, Chief Product & Data Officer
Horizon

“Traditional commerce media models often expose brands to unnecessary privacy risks by moving data into third-party environments. Our work with Narrative eliminates that risk while unlocking sophisticated audience-building capabilities that deliver real outcomes.”
Marni Schpario
Block

OTHER USE CASES
What an owned graph unlocks.

CLASSIFY
Turn raw data into structured signal.
Normalize, label, and categorize data inside your warehouse — with ML, LLMs, and human feedback in one loop. Cleaner inputs make every downstream use case sharper.
harper.

SECURELY COLLABORATE
Share data without ever shipping it.
Run collaboration in place — your data, your cloud, your governance. Make secure sharing the default, not the exception.
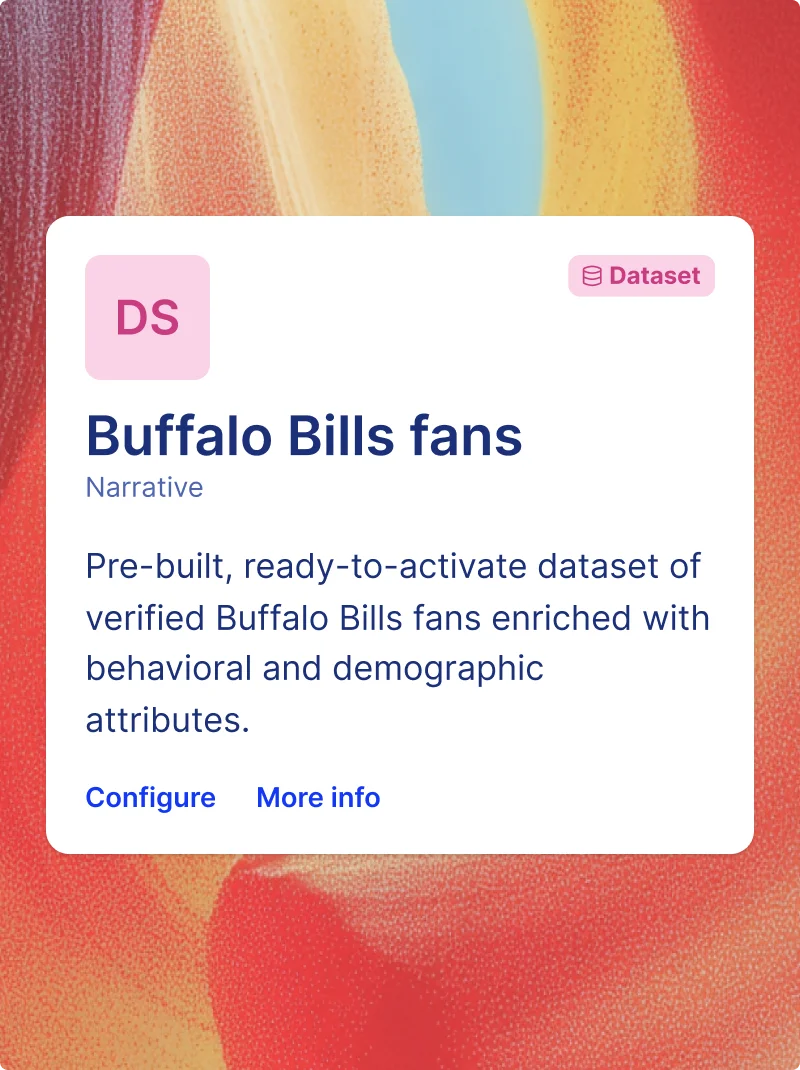
ENRICH
Add the attributes that make targeting precise.
Augment first-party data with a marketplace of normalized providers and hundreds of mapped attributes — joined to your customer file in your cloud, ready to drive segmentation, targeting, and measurement.
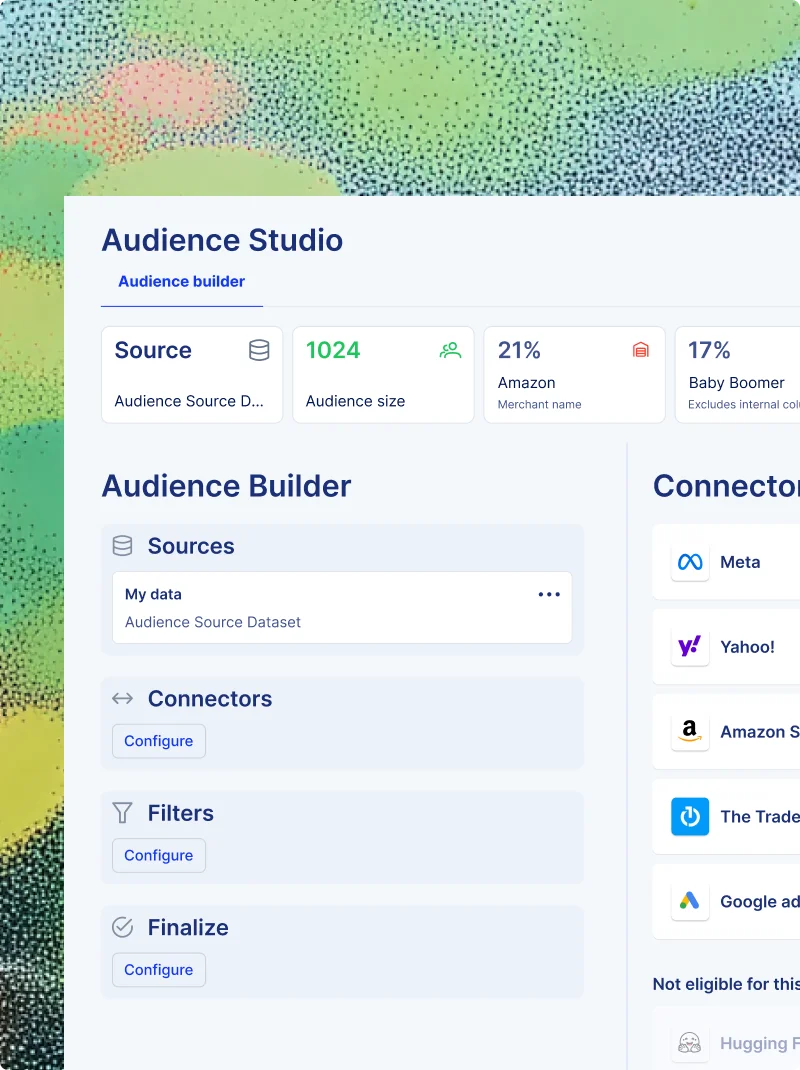
ACTIVATE AUDIENCES
Get audiences from definition to delivery in hours.
Push resolved-person audiences to every DSP, ad platform, and CRM with pre-built Connectors. Compliance rides along; activation lag goes away.

MONETIZE
Sell your data, keep your control.
Package, price, and license data on your terms. Buyers query it in place under your contracts and access rules with no bulk shipping, and no per-buyer custom prep.
Resources
Insights, stories, & resources for the teams building modern data infrastructure.
Blog
•
4
Mins
Narrative Reimagines the Marketplace: A Composable Hub for Data and AI Work


Blog
•
4
Mins
With Publicis' Acquisition of LiveRamp, Switzerland Just Picked a Side

Blog
•
4
Mins
Clean Rooms Were Necessary. They Were Never Enough.

Blog
•
3
Mins
Activate Your Audiences Across PubMatic's Sell-Side Platform



Blog
•
4
Mins
Data Marketplaces Should Work Like Infrastructure, Not Catalogs
Ask Us Anything
Straight answers to real customer questions.
Most teams are normalizing live data within days of connecting their first sources — not months. There's no multi-quarter implementation, no professional services dependency, no bespoke build required. You connect your sources, define what coherence looks like for your use case, and Narrative does the translation work. The timeline question is usually less about setup and more about how quickly your team can act on data that's finally consistent.
Those tools move data and act on it. They don't normalize it. They're built on the assumption that the data arriving is already clean, consistent, and semantically coherent — and in most real-world data partnerships, it isn't. Narrative is the layer that makes your existing collaboration and activation infrastructure work the way it was designed to. The teams getting the most from their data stack are typically the ones who've solved normalization first.
Most teams do, at first. The problem isn't the initial build — it's everything after. Every partner schema change breaks it. Every new data source requires rebuilding it. Every team transition means relearning it. The engineering debt compounds faster than the business value accrues. Narrative replaces a perpetual maintenance burden with infrastructure that's designed to absorb that complexity so your team doesn't have to.
Data and analytics teams at companies where external data is a core business input — not a supplement. Typically organizations that are buying data at scale, monetizing their own data assets, or running structured data partnerships with other companies. If your team is spending meaningful engineering time just making external data usable, that's the problem Narrative is built to eliminate.
AI models don't tolerate inconsistency. When a "user" in one dataset isn't recognized as the same "user" in another — different schemas, different taxonomies, different identifiers — your models train on noise and your outputs reflect it. Narrative normalizes data at the source so the AI layer above it is working with signal. Garbage in, garbage out isn't an AI problem. It's a normalization problem.
Your warehouse stores data. Your CDP activates it. Narrative normalizes it — resolving the semantic inconsistencies that make data from different sources incompatible before it ever reaches those tools. We don't replace your stack. We fix the layer underneath it that your stack assumes is already solved.