Most data teams don't struggle because they lack tools. They struggle because their data doesn't line up.
Different schemas. Different naming conventions. Slightly different interpretations of the same concept across sources. Nothing is obviously broken, but nothing is perfectly aligned either.
That misalignment is where friction lives. Normalization is what fixes it.
Rosetta AI already does the hard work of automatically normalizing messy, inconsistent data into structured, interoperable formats. But until now, much of that work has happened behind the scenes.
We're changing that.
We're introducing a new view inside the Rosetta Stone Normalization Engine that lets you see how your data was normalized, how confident the system is, and where human review improves outcomes.
This is a foundational step in the evolution of Rosetta Stone: make messy data structured, and make that transformation visible, understandable, and controllable.
Normalization shouldn't feel like magic. It should feel like working alongside an intelligent system you can trust.
Why visibility matters
Normalization is infrastructure. When it works, no one notices. When it doesn't, everything downstream feels unstable.
Historically, normalization systems operate like this: data goes in, a "cleaned" dataset comes out, and teams trust that it's correct — or discover later that something subtle was off. That model doesn't scale.
If identity graphs, audience activation, analytics, and data products depend on normalized inputs, teams need to understand:
- What was transformed
- How confident the system is
- Where review is recommended
- Which mappings were AI-generated
Trust comes from understanding how the work was done. This new Rosetta Stone view brings that understanding directly into the workflow.
What's new: A View Into Your Normalized Datasets
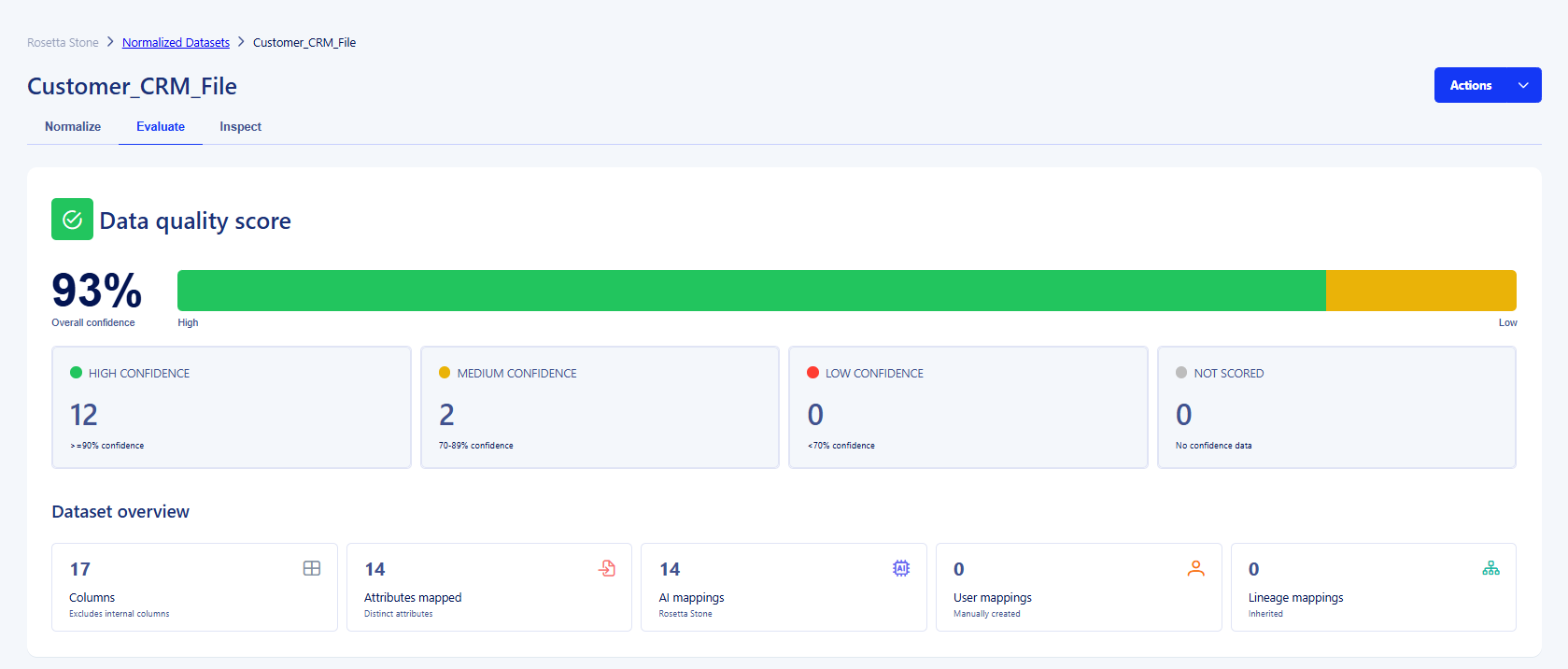
Inside Rosetta Stone, you can now see every dataset processed through the normalization engine — along with key signals that help you assess readiness.
At a glance, you can:
- View all normalized datasets in one place
- See dataset-level average confidence scores
- Identify which datasets are ready to use and which may need review
- Inspect detailed AI-generated mapping suggestions
Confidence levels are clearly surfaced:
- High confidence (90%+) — likely ready for downstream use
- Medium confidence (70–89%) — review recommended
- Low confidence (<70%) — human input encouraged
Instead of guessing whether normalization "looks right," you get clear signals before data flows into activation, analytics, or identity workflows.
Powered by Rosetta AI, guided by you
As always, Rosetta AI isn't about replacing human judgment. It's about focusing review where it matters.
It doesn't just "guess" at your schema. It analyzes dataset structure, column names, sample values, and semantic context — then maps those fields to a universal attribute layer that standardizes meaning across datasets.
Under the hood, Rosetta AI combines:
- LLM-powered semantic understanding to interpret what fields represent
- Trained classifiers and similarity models to validate and refine mappings
- Row-level normalization logic to standardize emails, phones, names, addresses, and other identifiers
- Feature extraction to prepare data for matching and identity resolution
The result is structured, interoperable data that can be used consistently across identity graphs, audience workflows, and downstream analytics.
So, what's new in this release isn't the intelligence. It's the visibility into output.
You can now see several aspects of that system directly in the UI — including which mappings were AI-generated, how confident the system is, and where human review is recommended.
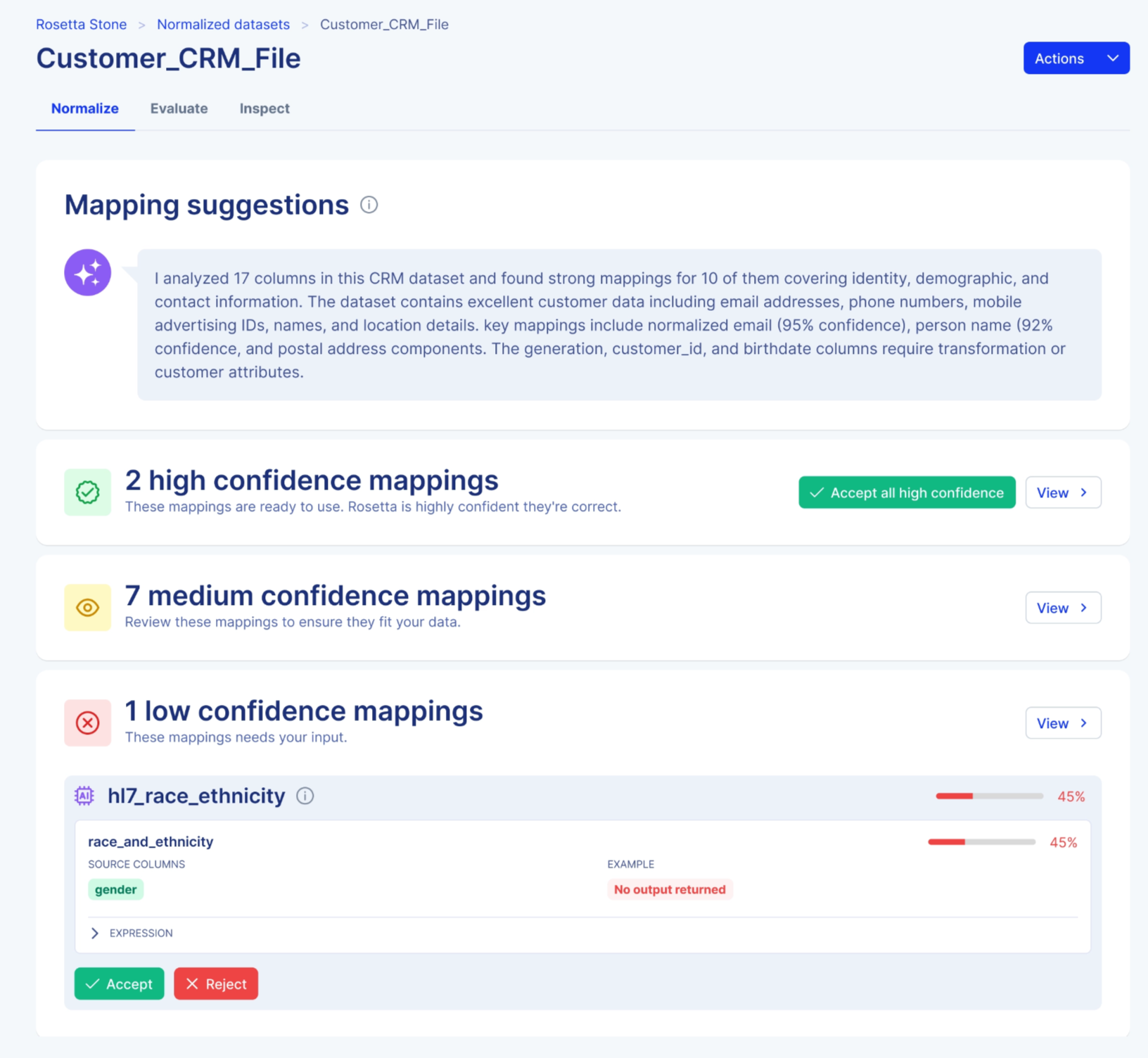
When reviewing mappings, you can:
- See AI-generated suggestions grouped by confidence
- Bulk-accept high-confidence mappings
- Review or adjust medium-confidence mappings
- Refine low-confidence transformations
- Provide feedback that improves future results
The result is collaborative normalization: automation first, human insight where needed.
Over time, that feedback loop strengthens model performance and builds institutional confidence in the engine.
Who this is for
This view is built for teams responsible for data quality and downstream reliability.
If you've ever had to answer, "How confident are we in this data?" then this release is for you.
What this unlocks
With clearer visibility into normalization:
- Identity graphs rebuild on more reliable foundations
- Audience sizing and activation become more predictable
- Data products inherit structured, consistent inputs
- Compliance teams gain clearer transformation oversight
Rosetta AI handles normalization at scale. This release ensures you can see and guide that work. Normalization moves from background automation to an active, transparent part of your workflow.
And that shift matters.
Built for where Rosetta Stone is headed
Normalization isn't a feature, it's the infrastructure.
Rosetta Stone uses a shared attribute layer to create a common semantic language across datasets. LLMs and machine learning models interpret raw schemas and map them to that layer. Row-level normalization standardizes values for comparability. Feature extraction prepares data for matching and identity workflows.
All of that happens before data is activated, analyzed, or shared.
If you want a deeper look at how Rosetta Stone works under the hood, we break it down here:
How Narrative Rosetta Stone Transforms Identity Resolution →
This release makes that foundation visible.
Rosetta AI continues to do the heavy lifting: aligning, structuring, and normalizing messy data at scale. What's new is your ability to see how it was done, assess confidence before activation, and guide improvements where precision matters.
When normalization is both automated and transparent, everything built on top of it becomes more reliable.
And that shift matters.
Available now
This new normalization view is generally available to contracted customers. If you're already using Narrative, you can access it today within: Rosetta Stone